Local LLM models: Part 1 - getting started
This will be a series of posts about running LLMs locally. By the end we should have our own web based chat interface which can call tools we have defined - e.g. to use a web search API, retrieve pages and feed them back into the model.
This post covers the first steps:
You’ll need a machine with a GPU with at least 16 GB memory for decent performance. I’m using a Linux box with a 24 GB Nvidia RTX 3090 GPU, 64 GB DDR4 RAM and 8 core, 16 thread AMD Ryzen 7 CPU. Using a machine with an integrated GPU where acceleration is supported such as Apple M series should also work provided you have enough memory.
Downloading and building llama.cpp
There are a number of different possibilities to run model inference locally. I’m going with llama.cpp as it’s efficient, easy to setup and supports a wide range of open weights models. The code ggml library is written in C++ with optimised CPU BLAS code and acceleration on GPU (CUDA, Metal, HIP, Vulkan etc.).
It’s best to build from source to get the latest version compiled for your hardware. See the build instructions for details. e.g. If we have a NVIDIA GPU with CUDA toolkit installed:
git clone https://github.com/ggml-org/llama.cpp
cd llama.cpp
cmake -B build -DGGML_CUDA=ON
cmake --build build --config Release -j 8
That will create the build subdirectory and all of the tools under llama.cpp/build/bin
Downloading and running the gpt-oss-20b model
There are many models in GGUF format which you can download to run with llama.cpp. I’m going with gpt-oss-20b here as it’s optimized to run in under 16GB so we can fit the entire model on a single consumer GPU. For details on the model architecture see here.
Download the model from huggingface.co/unsloth/gpt-oss-20b-GGUF. This is a conversion of the original model released by OpenAI to the GGUF format used by llama.cpp plus some template fixes. Total size is around 13GB as the MOE (Mixture-of-Experts) weights which make up most of the size are quantized in MXFP4 format while the rest are BF16. There’s no benefit in going for the other quantized files in the same repository.
mkdir gguf
cd gguf
wget https://huggingface.co/unsloth/gpt-oss-20b-GGUF/resolve/main/gpt-oss-20b-F16.gguf
To run the server:
./llama.cpp/build/bin/llama-server -m ./gguf/gpt-oss-20b-unsloth-F16.gguf \
--host 127.0.0.1 --port 8080 --ctx-size 32768 --keep 200 \
--jinja -ub 2048 -b 2048 -ngl 99 -fa
The parameters are:
--host 127.0.0.1to set listen for requests on localhost - change to 0.0.0.0 to bind to all interfaces--port 8080listen port for web server - default--ctx-size 32768to set maximum context size in tokens - default is 131072 as defined in the gguf file--keep 200to set number of tokens to keep if context size exceeded--jinjause the built in chat template in the gguf file - this converts messages to the OpenAI harmony response format-ub 2048-b 2048batch size (as suggested here)-ngl 99number of GPU layers - i.e. run all layers on GPU-faenable flash attention - should improve performance
See the full docs for more.
Using the builtin llama-server web chat
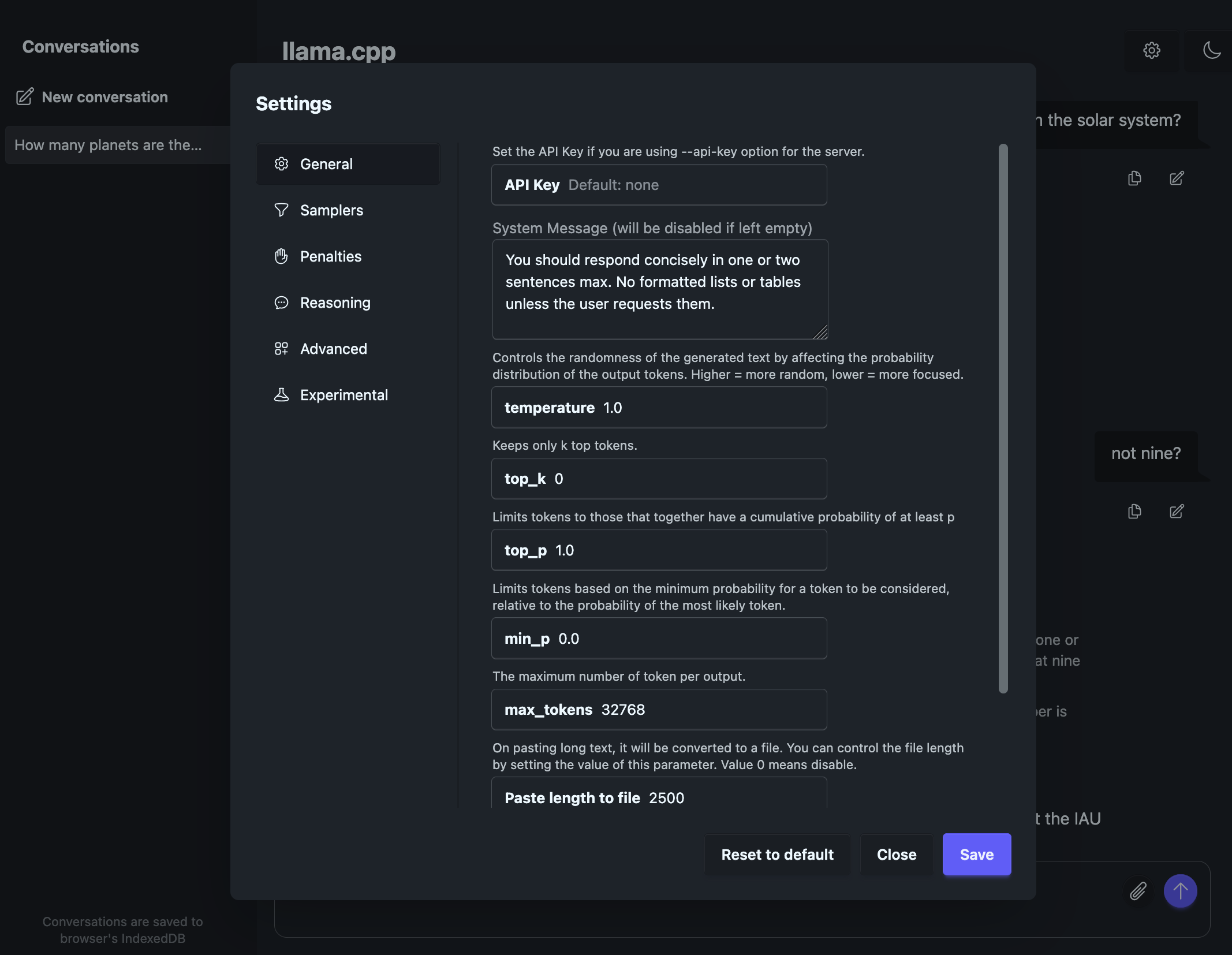
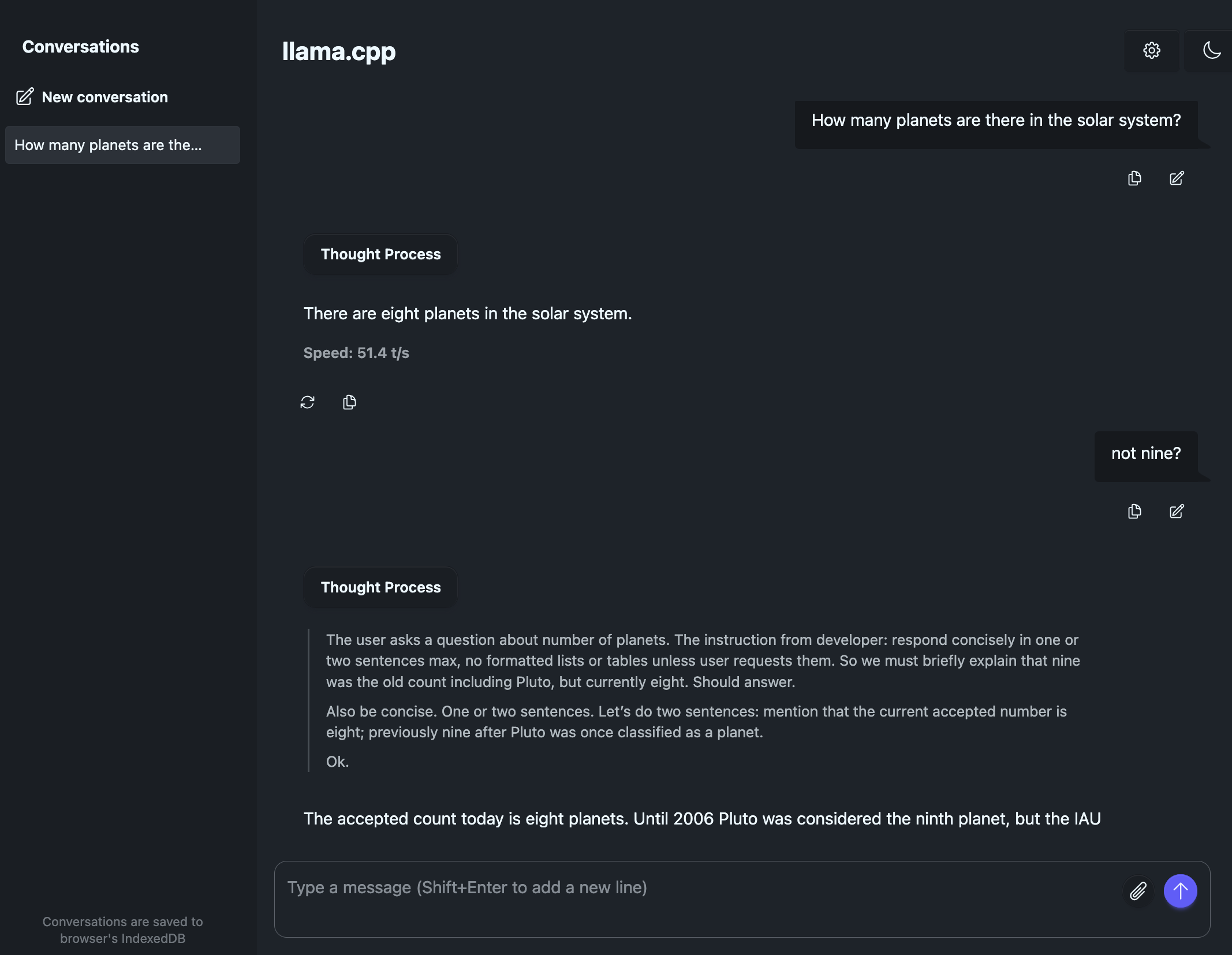
Just point your browser to http://localhost:8080 and you’ll see the web interface.
The sampling parameters recommended by OpenAI are temperature=1.0 top-p=1.0 top-k=0.
In the example below I’ve set these plus also set a custom system prompt.
The interface will stream output from the model showing chain of thought followed by the final response. Performance is pretty good - around 50 tokens/sec.
 |  |
Running gpt-oss-120b
The bigger 120 billion parameter flavour of the model is a 61 GB download. I don’t have enough GPU memory to load
the entire model in VRAM but as per this reddit thread we can use the --n-cpu-moe parameter to offload some or all of the MOE layers
to run on CPU while running the rest on GPU.
Running the model with these params:
./llama.cpp/build/bin/llama-server -m ./gguf/gpt-oss-120b-unsloth-F16.gguf \
--host 127.0.0.1 --port 8080 --ctx-size 32768 --keep 200 \
--jinja -ub 2048 -b 2048 -ngl 99 -fa --n-cpu-moe 28
uses around 20GB GPU VRAM + 54GB system RAM. On my system the performance is around 11.5 tokens/sec. Not as snappy as the smaller model but still pretty usable. As you’d expect from the larger model it has a larger fact base. e.g. gpt-oss-20b vs gpt-oss-120b.
For the next post in this series go to part 2 which introduces calling the model via the Completions API in go.